Abstract
3D object detection is an important scene understanding task in autonomous driving and virtual reality. Approaches based on LiDAR technology have high performance, but LiDAR is expensive. Considering more general scenes, where there is no LiDAR data in the 3D datasets, we propose a 3D object detection approach from stereo vision which does not rely on LiDAR data either as input or as supervision in training, but solely takes RGB images with corresponding annotated 3D bounding boxes as training data. As depth estimation of object is the key factor affecting the performance of 3D object detection, we introduce an Instance-Depth-Aware (IDA) module which accurately predicts the depth of the 3D bounding box’s center by instance-depth awareness, disparity adaptation and matching cost reweighting. Moreover, our model is an end-to-end learning framework which does not require multiple stages or postprocessing al- gorithm. We provide detailed experiments on KITTI benchmark and achieve impressive improvements compared with the existing image-based methods.
Overview
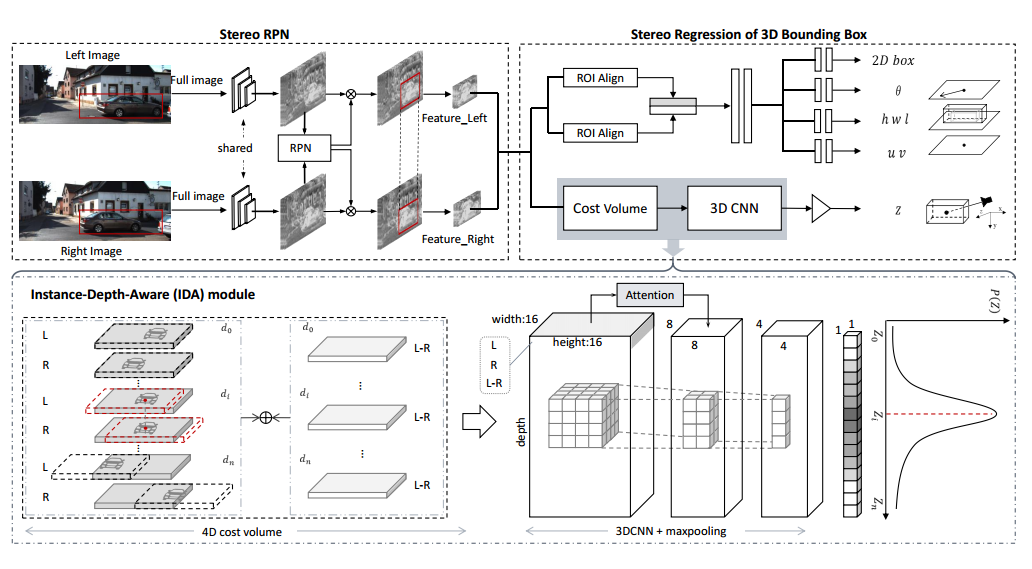
Overview of the proposed IDA-3D. Top: Stereo RPN takes a pair of left and right images as input and outputs corresponding left- right proposal pairs. After stereo RPN, we predict position, dimensions and orientation of 3D bounding box. Bottom: Instance-depth-aware module builds a 4D cost volume and performs 3DCNN to estimate the depth of a 3D bounding box center.
Results

Quantitative results on several scenes in KITTI dataset. At the first row are the ground truth 3D boxes and the predicted 3D boxes projected to the image plane. We also show the detection results on point cloud in order to facilitate observation. The predicted results are shown in yellow and the ground truth are shown in blue.
BibTeX
@InProceedings{Peng_2020_CVPR,
author = {Peng, Wanli and Pan, Hao and Liu, He and Sun, Yi},
title = {IDA-3D: Instance-Depth-Aware 3D Object Detection From Stereo Vision for Autonomous Driving},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2020}
}