Abstract
Category-level 6D pose estimation can be better generalized to unseen objects in a category compared with instance- level 6D pose estimation. However, existing category-level 6D pose estimation methods usually require supervised training with a sufficient number of 6D pose annotations of objects which makes them difficult to be applied in real scenarios. To address this problem, we propose a self-supervised framework for category-level 6D pose estimation in this paper. We leverage DeepSDF as a 3D object representation and design several novel loss functions based on DeepSDF to help the self-supervised model predict unseen object poses without any 6D object pose labels and explicit 3D models in real scenarios. Experiments demonstrate that our method achieves comparable performance with the state-of-the-art fully supervised methods on the category-level NOCS benchmark.
Overview
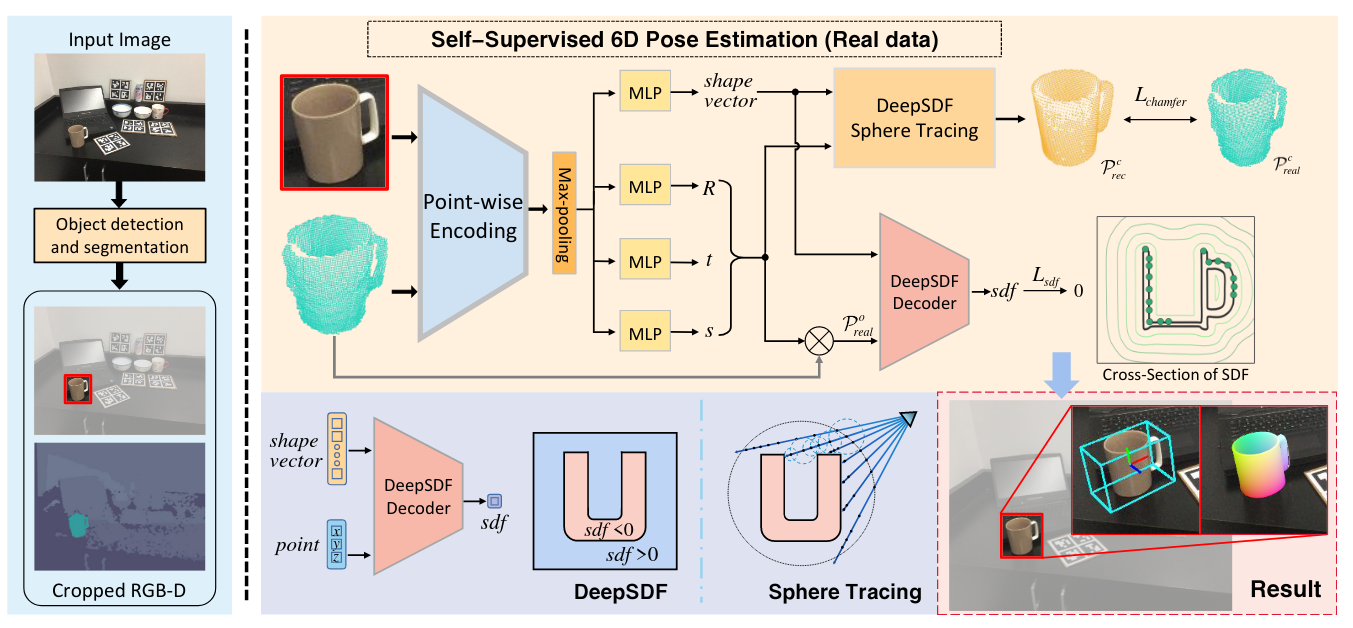
Overview of the proposed method. After segmenting individual object instances from the cluttered scene, we build an end-to-end network to jointly predict the rotation, translation, scale and shape latent vector of the object. Several self-supervised loss functions are designed to constrain consistency between predicted parameters and object observations in real-world data.
Results

Qualitative results on NOCS-REAL test set. The top row shows the estimated pose and size of every object with the axis and tight bounding box. The bottom row shows its reconstructed model rendered on the corresponding RGB image
BibTeX
@inproceedings{peng2022self,
title={Self-Supervised Category-Level 6D Object Pose Estimation with Deep Implicit Shape Representation},
author={Peng, Wanli and Yan, Jianhang and Wen, Hongtao and Sun, Yi},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={36},
number={2},
pages={2082--2090},
year={2022}
}